背景
HashedWheelTimer 本质是一种类似延迟任务队列的实现,适用于对时效性不高的,可快速执行的,大量这样的“小”任务,能够做到高性能,低消耗。
时间轮是一种非常惊艳的数据结构。其在 Linux 内核中使用广泛,是 Linux 内核定时器的实现方法和基础之一。Netty 内部基于时间轮实现了一个 HashedWheelTimer 来优化 I/O 超时的检测。
因为 Netty 需要管理上万的连接,每个连接又会有发送超时、心跳检测等,如果都使用 Timer 定时器的话,将耗费大量的资源。
在 Netty 中的一个典型应用场景是判断某个连接是否 idle,如果 idle(如客户端由于网络原因导致到服务器的心跳无法送达),则服务器会主动断开连接,释放资源。得益于 Netty NIO 的优异性能,基于 Netty 开发的服务器可以维持大量的长连接,单台 8 核 16G 的云主机可以同时维持几十万长连接,及时掐掉不活跃的连接就显得尤其重要。
延迟任务方案都有哪些?优缺点?
数据库轮询:数据先保存在数据库中,然后启动一个定时任务,根据时间和状态将待完成的任务数据捞出来,处理完成后再更新数据库。这种方法比较简洁,但是依赖数据库,同时如果任务数据量很大(千万)且的话,会存在数据库读写性能问题,且数据库读写可能占用大量时间,甚至超过任务处理的时间。有点是数据可以持久化,服务重启不丢失,并且可以查询管理未完成的任务。DelayQueue本质是一个 PriorityQueue,每次插入和删除都调整堆,时间复杂度是 O(longN),而 HashedWheelTimer 的时间复杂度是 O(1)。ScheduledExecutorService,JDK 的 ScheduledExecutorService 本质上仍然是一个 DelayQueue,但是任务是通过多线程的方式进行。
源码分析
使用示例
源码分析首先通过一个使用示例开始,HashedWheelTimer 一个典型的使用方法如下:
@Test
public void test() throws InterruptedException {
HashedWheelTimer wheelTimer = new HashedWheelTimer();
wheelTimer.newTimeout(timeout -> System.out.println("1s delay"), 1, TimeUnit.SECONDS);
wheelTimer.newTimeout(timeout -> System.out.println("10s delay"), 10, TimeUnit.SECONDS);
wheelTimer.newTimeout(timeout -> System.out.println("11s delay"), 11, TimeUnit.SECONDS);
TimeUnit.SECONDS.sleep(20);
}
在新建一个 HashedWheelTimer 对象实例后,可以向里面添加一个延迟任务,需要指定任务 TimerTask,延迟时间。
DOC 文档
官方的 4.0 版本的 doc 文档:https://netty.io/4.0/api/io/netty/util/HashedWheelTimer.html
Timer optimized for approximated I/O timeout scheduling.
Tick Duration
As described with 'approximated', this timer does not execute the scheduledTimerTask on time. HashedWheelTimer, on every tick, will
check if there are any TimerTasks behind the schedule and execute
them.
You can increase or decrease the accuracy of the execution timing by specifying smaller or larger tick duration in the constructor. In most network applications, I/O timeout does not need to be accurate. Therefore, the default tick duration is 100 milliseconds and you will not need to try different configurations in most cases.
Ticks per Wheel (Wheel Size)
HashedWheelTimer maintains a data structure called 'wheel'.
To put simply, a wheel is a hash table of TimerTasks whose hash
function is 'dead line of the task'. The default number of ticks per wheel
(i.e. the size of the wheel) is 512. You could specify a larger value
if you are going to schedule a lot of timeouts.
Do not create many instances.
HashedWheelTimer creates a new thread whenever it is instantiated and
started. Therefore, you should make sure to create only one instance and
share it across your application. One of the common mistakes, that makes
your application unresponsive, is to create a new instance for every connection.
Implementation Details
HashedWheelTimer is based on
George Varghese and
Tony Lauck's paper,
'Hashed
and Hierarchical Timing Wheels: data structures to efficiently implement a
timer facility'. More comprehensive slides are located
here.我们可以看出,HashedWheelTimer 是一个为 I/O 超时而定制的任务调度系统。
源码详细分析(略长)
示例中将一个任务放入 wheelTimer 中,下面代码会在 1 秒钟后,打印出 1s delay:
wheelTimer.newTimeout(timeout -> System.out.println("1s delay"), 1, TimeUnit.SECONDS);
其方法签名是:
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit)
这里面涉及到了两个类:Timeout 和 TimerTask。
其中 Timeout 的接口定义:
/**
* A handle associated with a {@link TimerTask} that is returned by a
* {@link Timer}.
*/
public interface Timeout {
/**
* Returns the {@link Timer} that created this handle.
*/
Timer timer();
/**
* Returns the {@link TimerTask} which is associated with this handle.
*/
TimerTask task();
/**
* Returns {@code true} if and only if the {@link TimerTask} associated
* with this handle has been expired.
*/
boolean isExpired();
/**
* Returns {@code true} if and only if the {@link TimerTask} associated
* with this handle has been cancelled.
*/
boolean isCancelled();
/**
* Attempts to cancel the {@link TimerTask} associated with this handle.
* If the task has been executed or cancelled already, it will return with
* no side effect.
*
* @return True if the cancellation completed successfully, otherwise false
*/
boolean cancel();
}
TimerTask 的接口定义:
/**
* A task which is executed after the delay specified with
* {@link Timer#newTimeout(TimerTask, long, TimeUnit)}.
*/
public interface TimerTask {
/**
* Executed after the delay specified with
* {@link Timer#newTimeout(TimerTask, long, TimeUnit)}.
*
* @param timeout a handle which is associated with this task
*/
void run(Timeout timeout) throws Exception;
}
还涉及到了一个 Timer 接口:
/**
* Schedules {@link TimerTask}s for one-time future execution in a background
* thread.
*/
public interface Timer {
/**
* Schedules the specified {@link TimerTask} for one-time execution after
* the specified delay.
*
* @return a handle which is associated with the specified task
*
* @throws IllegalStateException if this timer has been {@linkplain #stop() stopped} already
* @throws RejectedExecutionException if the pending timeouts are too many and creating new timeout
* can cause instability in the system.
*/
Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);
/**
* Releases all resources acquired by this {@link Timer} and cancels all
* tasks which were scheduled but not executed yet.
*
* @return the handles associated with the tasks which were canceled by
* this method
*/
Set<Timeout> stop();
}
Timer, TimerTask, Timeout 三者的关系为:
- Timer:管理 TimerTask,HashedWheelTimer 也是实现了 Timer 接口
- TimerTask:通过上述的 Timer.newTimeout(TimerTask, long, TimeUnit) 加入,在指定时间后执行的 Task
- Timeout:持有上层的 Timer 实例,和下层的 TimerTask 实例,然后取消任务的操作也在这里面。
类中的 field 如下:
private final ResourceLeakTracker<HashedWheelTimer> leak;
private final Worker worker = new Worker();
private final Thread workerThread;
public static final int WORKER_STATE_INIT = 0;
public static final int WORKER_STATE_STARTED = 1;
public static final int WORKER_STATE_SHUTDOWN = 2;
@SuppressWarnings({ "unused", "FieldMayBeFinal" })
private volatile int workerState; // 0 - init, 1 - started, 2 - shut down
private final long tickDuration;
private final HashedWheelBucket[] wheel;
private final int mask;
private final CountDownLatch startTimeInitialized = new CountDownLatch(1);
private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue();
private final Queue<HashedWheelTimeout> cancelledTimeouts = PlatformDependent.newMpscQueue();
private final AtomicLong pendingTimeouts = new AtomicLong(0);
private final long maxPendingTimeouts;
private volatile long startTime;
其中比较重要的有:
private final Worker worker = new Worker();
这个 Worker 是 HashedWheelTimer 的内部类,里面有核心的 run 逻辑,后面会详细分析。
worker 有 3 种状态 init, started, shutdown。
public static final int WORKER_STATE_INIT = 0;
public static final int WORKER_STATE_STARTED = 1;
public static final int WORKER_STATE_SHUTDOWN = 2;
核心是一个 HashedWheelBucket 类型的数组,里面保存了所有的定时任务。wheel 类似于 Java 里面的 HashMap,其中 HashedWheelBucket 每个桶都维护了一个未完成任务的链表。
private final HashedWheelBucket[] wheel;
private static final class HashedWheelBucket {
// Used for the linked-list datastructure
private HashedWheelTimeout head;
private HashedWheelTimeout tail;
其中 HashedWheelTimeout 就是上面 Timeout 接口的实现。
下面我们再从调用 io.netty.util.HashedWheelTimer#newTimeout 开始分析,整体代码再贴一遍,方便查看:
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}
前面是 task 和 unit 参数判空,分析时可以忽略。接下来是 pendingTimeouts 记录新插入的任务数量,每插入一个任务会原子加一,每个任务完成会原子减一。在插入的时候如果大于 maxPendingTimeouts,会拒绝插入(maxPendingTimeouts 默认是-1,不会进行任务数量的校验)。
接下来,就是 start() 方法,核心在于可能同时并发多个任务加入到 HashedWheelTimer 中,而此时 HashedWheelTimer 的任务还未启动,要确保只启动一次,当然加锁也可以,不过 HashedWheelTimer 的实现效率更高一些。
public void start() {
switch (WORKER_STATE_UPDATER.get(this)) {
case WORKER_STATE_INIT:
if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {
workerThread.start();
}
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
throw new IllegalStateException("cannot be started once stopped");
default:
throw new Error("Invalid WorkerState");
}
// Wait until the startTime is initialized by the worker.
while (startTime == 0) {
try {
startTimeInitialized.await();
} catch (InterruptedException ignore) {
// Ignore - it will be ready very soon.
}
}
}
接下来是计算任务的截止时间 deadline,其实很好理解,截止时间 deadline=当前时间+任务要延迟的时间-HashedWheelTimer 的启动时间。deadline 是相对于 startTime 的:
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
最终根据计算出来的 deadline,新建一个 HashedWheelTimeout 对象,并将对象加入到 timeout 队列中。
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
此时 timeout 仅仅是加入到了 Queue
@Override
public void run() {
// Initialize the startTime.
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
// Notify the other threads waiting for the initialization at start().
startTimeInitialized.countDown();
do {
final long deadline = waitForNextTick();
if (deadline > 0) {
int idx = (int) (tick & mask);
processCancelledTasks();
HashedWheelBucket bucket =
wheel[idx];
transferTimeoutsToBuckets();
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
// Fill the unprocessedTimeouts so we can return them from stop() method.
for (HashedWheelBucket bucket: wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (;;) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}
正常运行时程序一直都处在 while 循环中:
do {
final long deadline = waitForNextTick();
if (deadline > 0) {
int idx = (int) (tick & mask);
processCancelledTasks();
HashedWheelBucket bucket =
wheel[idx];
transferTimeoutsToBuckets();
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
其中 waitForNextTick() 方法是阻塞等到下个滴答的时间(默认时间是 100ms),判断应该使用 HashedWheelBucket[] wheel 中的哪个桶,取出这个桶中的任务并执行。expireTimeouts 方法如下:
public void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
next = remove(timeout);
if (timeout.deadline <= deadline) {
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
next = remove(timeout);
} else {
timeout.remainingRounds --;
}
timeout = next;
}
}
其核心逻辑就是获取桶的链表 head,依次判断该桶中所有任务是否有到期该执行的,有的话拿出来执行,并且在链表中删除该任务。核心 timeout.expire() 实现:
public void expire() {
if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {
return;
}
try {
task.run(this);
} catch (Throwable t) {
if (logger.isWarnEnabled()) {
logger.warn("An exception was thrown by " + TimerTask.class.getSimpleName() + '.', t);
}
}
}
里面核心就是执行了 run 方法,执行核心的任务逻辑。
io.netty.util.HashedWheelTimer.Worker#run 的 while 循环里还有一个 transferTimeoutsToBuckets 方法:
private void transferTimeoutsToBuckets() {
// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just
// adds new timeouts in a loop.
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
long calculated = timeout.deadline / tickDuration;
timeout.remainingRounds = (calculated - tick) / wheel.length;
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
bucket.addTimeout(timeout);
}
}
为了保证每次 tick 不会阻塞 run 方法,每次转移的任务不超过 10w 个。这个方法所做的就是将 Queue
至此代码已经分析完了,如下图所示(图片摘自:图片链接):
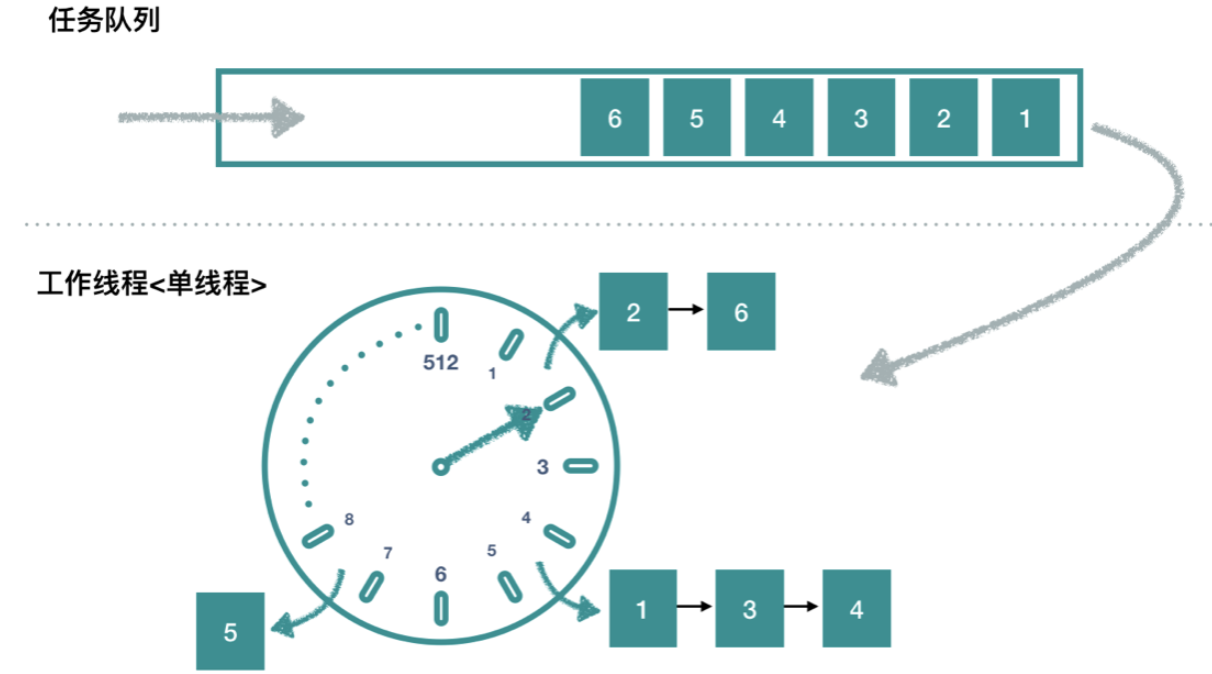
- HashedWheelTimer 模拟了时间的流转,默认新建了一个长度为 512 的桶,每隔 tick 单位时间,指针向前移动。
- HashedWheelTimer 新加入的任务,会放入 Queue
timeouts 队列中。 - HashedWheelTimer 内部使用一个线程,每隔 tick 单位时间处理一些逻辑,包括:
- 处理指针当前指向桶的任务队列,如果任务到到延迟时间,就执行任务并在对应桶中删除。
- 将 timeouts 队列的任务放入对应的桶中,每次最多处理 10w 个。
HashedWheelTimer 的特点
- 从源码分析可以看出,其实 HashedWheelTimer 的时间精度并不高,误差能够在 100ms 左右,同时如果任务队列中的等待任务数量过多,可能会产生更大的误差。
- 但是 HashedWheelTimer 能够处理非常大量的定时任务,且每次定位到要处理任务的候选集合链表只需要 O(1) 的时间,而 Timer 等则需要调整堆,是 O(logN) 的时间复杂度。
- HashedWheelTimer 本质上是
模拟了时间的轮盘,将大量的任务拆分成了一个个的小任务列表,能够有效节省 CPU 和线程资源。